
팀 프로젝트로 실제 서비스를 운영 중인 애플리케이션에 대한 성능 측정을 진행하고 성능 개선 작업을 진행한 내용을 공유하려고 합니다. Spring Boot, JPA, PostgreSQL, Thymeleaf 등 모놀리식 아키텍처(Monolithic Architecture)로 구성되어 있습니다.
이에 대한 내용은 운영 환경인 EC2에서 진행하지 않고 로컬 PC에서 먼저 진행했습니다.
성능 측정의 필요성
웹사이트의 로딩이 몇 초만 길어져도 사용자들은 기다리지 않기 때문에 이탈률은 급격히 증가하고, 이는 곧 매출 손실이나 사용자 불만으로 이어집니다. 하지만 성능 문제를 해결하려 할 때, 가장 먼저 해야 할 일은 단순한 속도 향상이 아니라 "어디가 느린지를 정확히 아는 것"이라고 생각합니다.
성능 문제를 해결하기 위해 가장 쉽고 간단하게 할 수 있는 방법은 서버 스펙을 높이거나, 서버 수를 늘릴 수 있습니다.
즉, 스케일업(Scale-up) 또는 스케일아웃(Scale-out) 전략입니다.
- 스케일업(Scale-up): 더 좋은 CPU, 더 많은 메모리 같은 상위 사양의 서버로 교체
- 스케일아웃(Scale-out): 서버 인스턴스를 수평으로 확장하여 분산 처리
위의 방법들은 단기적인 해결책으로 매우 효과적일 수 있습니다. 특히 트래픽 급증 상황이나 빠르게 대응해야 하는 경우에 유용하다고 생각합니다. 하지만 무작정 자원을 투입하는 방식은 한계가 명확합니다.
- 물리적 자원은 결국 한계가 존재
- 클라우드 환경에서는 비용이 기하급수적으로 증가
- 성능 병목이 코드나 구조 내부에 있다면, 아무리 자원을 늘려도 해결되지 않는 경우가 있을 수 있음
그래서 중요한 것은, 먼저 측정하고 지표(숫자)로 판단하는 것입니다.
성능이 느린 이유가 잘못된 쿼리, 불필요한 연산, 비효율적인 캐싱 전략 때문이라면, 하드웨어를 늘리기보다는 이유를 정확히 파악하고, 그 부분을 개선하는 것이 훨씬 효과적이고 지속 가능한 방법입니다.
성능 개선 목표
성능 개선에 대해 검색하면 성능 지표로 처리량(Throughput)과 지연 시간(Latency)에 대해서 많이 자료가 나왔었습니다.
- 처리량(Throughput): 단위 시간당 시스템이 처리할 수 있는 작업(트랜잭션, 요청 등)의 양
- 주로 사용하는 단위:
- TPS (Transcations Per Second): 시스템이나 서버가 1초 동안 처리할 수 있는 트랜잭션(요청) 수를 나타내는 성능 지표
- RPS (Requests Per Second): 시스템이나 서버가 1초 동안 처리할 수 있는 HTTP 요청 수를 나타내는 성능 지표(웹 서버 기준)
- 지연 시간 (Latency): 클라이언트가 한 건의 요청을 보낸 시점부터 응답을 받기까지 걸리는 시간
- 주로 사용하는 단위: 초(s), 밀리초(ms)
- 지연 시간은 여러 통계 값으로 표현:
- 평균 지연 시간(avg)
- p95 퍼센타일(Percentile): 전체 요청 중 95%는 p95 시간 이하로 응답을 받음(가장 느린 5%의 요청을 제외한 나머지 요청은 이 시간보다 빠르게 처리)
- p99 퍼센타일(Percentile): 전체 요청 중 99%는 p99 시간 이하로 응답을 받음(가장 느린 1%의 요청을 제외한 나머지 요청은 이 시간보다 빠르게 처리)
성능 개선 목표를 어떻게 해야 할지 경험이 없어서 막막했습니다. 그래서 제가 서비스를 사용했을 때의 경험으로 1~2초 정도는 기다리지만 그 이상 기다리면 바로 나갔던 기억이 있고, 주위의 반응도 비슷했습니다.
이 기준으로 지연 시간이 1~2초 이내로 개선하도록 목표를 정하고 시작했습니다.
성능 측정
성능을 측정하고 병목 현상을 파악하기 위해 APM(Application Performance Management) 도구로 'Pinpoint'를 사용했습니다.
많이 알려진 APM 도구로는 프로메테우스(Prometheus) + 그라파나(Grafana) 조합이 있습니다. 이들은 다양한 자료와 고급 대시보드, 뛰어난 확장성과 유연성 덕분에 널리 사용되고 있습니다.
하지만 제가 Pinpoint를 사용한 이유는 다음과 같습니다.
Pinpoint는 분산 애플리케이션 전반의 트랜잭션 흐름을 시각적으로 추적할 수 있도록 도와주며, 문제 구간이나 병목 현상을 더 직관적으로 파악할 수 있다고 느꼈기 때문입니다.
특히, 복잡한 서비스 구조에서 요청이 어떤 경로를 거쳐 처리되는지 한눈에 파악할 수 있는 기능은, 성능 분석과 원인 추적을 할 때 큰 도움이 될 것 같습니다.
Pinpoint에 대한 내용 및 설치는 다음의 링크를 참조하시기 바랍니다.
Pinpoint로 애플리케이션 성능 측정
더미 데이터
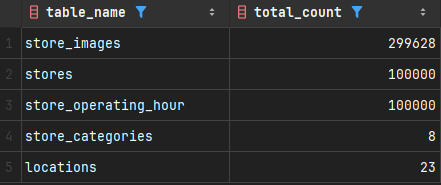

데이터는 팝업스토어 100,000개, 스토어 당 랜덤 이미지 1~5개로 299,628개, 주소 28개, 카테고리 8개로 구성했습니다.
부하 테스트는 'Postman'를 사용해 100VU(가상 유저)에 5분 동안 지속하도록 했습니다.
성능 측정 분석
Pinpoint 측정 화면
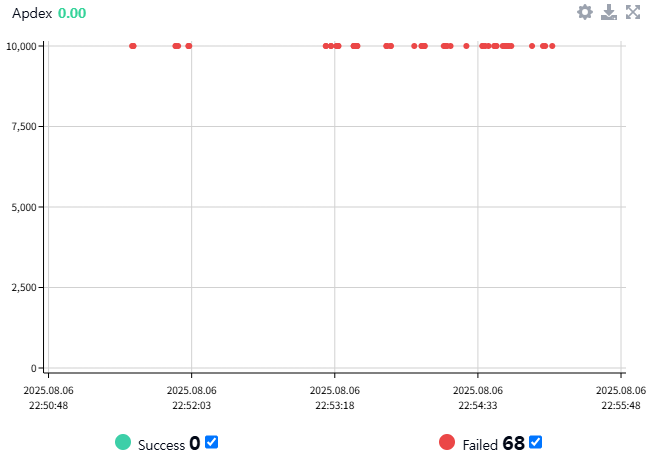


Postman 측정 화면

결과는 보다시피 처참했습니다. 에러율 100%로 모두 실패했습니다.
Pinpoint의 Call Tree에 보면 'SQLTransientConnectionException'이 발생했고, "HikariPool-1 - Connection is not avaliable, request timed out after 30052ms (total=10, active=10, idle=0, waiting=13)" 원인 내용이 출력되어 있습니다. 애플리케이션 콘솔 로그에도 마찬가지로 같은 내용이 있었습니다.

SQLTransientConnectionException의 내용은 다음과 같습니다.
HikariCP 커넥션 풀에서 커넥션을 가져오지 못해 타임아웃이 발생했습니다. 커넥션을 기다렸지만, 약 30초(default connection timeout 30초) 동안 응답이 없어 실패했습니다.
- total=10: 커넥션 풀에 존재하는 총 커넥션 수(default 값 10개)
- active=10: 현재 사용 중인 커넥션 수
- idle=0: 대기 중인 커넥션 없음
- waiting=13: 커넥션을 얻으려고 대기 중인 요청 수
갑작스러운 트래픽 증가로 커넥션 부족 현상이 발생했고, SQL 쿼리가 느려 커넥션이 오랫동안 점유하고 있어서 발생한 문제라고 생각했습니다. SQL 쿼리 시간이 오래 걸리는 것을 확인했으니 쿼리 성능을 개선하기 전에 쿼리가 어떻게 실행되고 있는지 확인하고 문제점을 확인해 보겠습니다.
SQL 쿼리 확인
현재 코드는 JPA의 Query Method를 사용하여 아래와 같이 구현되어 있습니다.
return storeRepository.findAllByStoreStatusAndIsDeletedFalse(status).stream()
.map(StoreThumbnailResponse::from)
.toList();
이 코드 실행 시 다음과 같은 SQL 쿼리들이 발생했습니다.
select id, category_id, created_at, description, end_date,
is_deleted,location_id, name, sns_url, start_date, store_status,
updated_at, view_count, website_url
from stores
where store_status=? and not (is_deleted);
select store_id, id, created_at, image_url, is_deleted, is_thumbnail, updated_at
from store_images
where store_id=?;
select id, created_at, name, updated_at
from store_categories
where id=?;
select id, address, address_detail, created_at, latitude, longitude,
name, sido, sigungu, updated_at, zonecode
from locations
where id=?;
select store_id, id, created_at, image_url, is_deleted, is_thumbnail, updated_at
from store_images
where store_id=?;
select store_id, id, created_at, image_url, is_deleted, is_thumbnail, updated_at
from store_images
where store_id=?;
select store_id, id, created_at, image_url, is_deleted, is_thumbnail, updated_at
from store_images
where store_id=?;
select store_id, id, created_at, image_url, is_deleted, is_thumbnail, updated_at
from store_images
where store_id=?;
현재 stores, store_images 테이블에는 각각 5개의 데이터만 존재합니다.(SQL 쿼리 확인용)
그럼에도 불구하고 store_images 테이블에 대한 쿼리가 5번이나 반복되고 있는 것을 확인할 수 있습니다. 이는 JPA의 대표적인 성능 문제인 N+1 문제가 발생한 것입니다.
N+1 문제
다음 코드를 보면 문제가 발생한 원인을 이해할 수 있습니다.
final String thumbnailUrl = store.getStoreImages().stream()
.filter(StoreImage::isThumbnail)
.findFirst()
.map(StoreImage::getImageUrl)
.orElse(null);
StoreThumbnailResponse::from 메서드 내부에서 store.getStoreImages()를 호출하고 있습니다. 이로 인해 각 store 객체에 대해 store_images 테이블을 개별적으로 조회하는 쿼리가 발생합니다.
@OneToMany(mappedBy = "store", cascade = CascadeType.ALL, orphanRemoval = true)
private List<StoreImage> storeImages = new ArrayList<>();
@OneToMany 관계는 기본적으로 지연 로딩(fetch = LAZY) 전략을 사용합니다. 즉, store.getStoreImages()를 호출하는 시점에 데이터베이스에 추가적인 SELECT 쿼리가 발생합니다.
JPA 연관 관계의 기본 Fetch 전략
@OneToMany: LAZY
@ManyToOne: EAGER
@ManyToMany: LAZY
@OneToOne: EAGER
지연 로딩(LAZY)의 동작 방식
JPA에서 지연 로딩은 실제 연관 엔티티를 즉시 조회하지 않고, 프록시 객체(Hibernate는 CGLIB 프록시)를 통해 참조만 유지합니다. 이 프록시는 실제 데이터를 갖고 있지 않으며, 해당 엔티티의 데이터를 사용하려는 시점에 DB에서 쿼리를 실행해 실제 데이터를 로딩하게 됩니다.
그렇다고 지연 로딩 전략에서만 N+1 문제가 발생하는 것은 아닙니다.
N+1 문제에 대한 자세한 내용은 이 컨텐츠에서 다루지 않겠습니다.
왜 5개 중 4개만 쿼리가 발생했을까?
처음 쿼리에서는 store_images가 5개 모두 조회되지 않고, 4개의 추가 쿼리만 발생한 것을 볼 수 있습니다.
이유는 JPA의 영속성 컨텍스트(Persistence Context) 덕분입니다. JPA는 이미 조회한 연관 데이터를 1차 캐시에 보관하고, 같은 엔티티에 대해 중복 쿼리를 발생시키지 않습니다.
즉, 첫 번째 store의 store_images는 이미 로딩되어 있어서, 이후 동일한 ID에 대해서는 DB를 다시 조회하지 않고 캐시에서 값을 가져오게 됩니다.
1차 캐시란?
- JPA의 영속성 컨텍스트는 엔티티 매니저 내부에 존재하며, 이미 조회한 엔티티를 메모리에 저장합니다.
- 이 덕분에 동일한 엔티티에 대해 반복적인 DB 접근 없이 성능을 최적화할 수 있습니다.
N+1 문제 개선
N+1 문제를 해결하는 방법에는 다음과 같은 방식들이 있습니다:
- Fetch Join을 활용한 JPQL 작성
- @EntityGraph 사용
- QueryDSL을 활용한 쿼리 구성
이처럼 다양한 방법이 있지만, 저는 이번에 Fetch Join 대신 DTO Projection을 사용하여 N+1 문제를 해결했습니다.
코드의 내용은 다음과 같습니다.
@Repository
public class StoreRepositoryImpl implements StoreRepositoryCustom {
@PersistenceContext
private EntityManager em;
@Override
public List<StoreThumbnailResponse> findAllByStoreStatus(final StoreStatus storeStatus) {
return em.createQuery("""
select new kr.co.pinup.stores.model.dto.StoreThumbnailResponse(
s.id,
s.name,
s.storeStatus,
s.startDate,
s.endDate,
c.name,
l.sigungu,
si.imageUrl)
from Store s
join s.category c
join s.location l
left join s.storeImages si
on si.isThumbnail = true
where s.storeStatus = :storeStatus
and s.isDeleted = false
""", StoreThumbnailResponse.class)
.setParameter("storeStatus", storeStatus)
.setMaxResults(1000)
.getResultList();
}
}
Fetch Join을 사용하면 연관된 엔티티까지 한 번에 불러올 수 있지만, 엔티티 전체를 메모리에 로딩하게 되어 불필요한 데이터까지 조회되는 경우가 많습니다.
이번 요구사항에서는 화면에 필요한 일부 필드만 조회하면 충분했기 때문에, JPQL에서 DTO로 직접 매핑하는 방식을 사용했습니다.
다음은 위 JQPL을 통해 실제로 실행되는 SQL입니다.
select
s1_0.id,
s1_0.name,
s1_0.store_status,
s1_0.start_date,
s1_0.end_date,
c1_0.name,
l1_0.sigungu,
si1_0.image_url
from stores s1_0
join store_categories c1_0 on c1_0.id=s1_0.category_id
join locations l1_0 on l1_0.id=s1_0.location_id
left join store_images si1_0 on s1_0.id=si1_0.store_id
and si1_0.is_thumbnail=true
where s1_0.store_status='RESOLVED'
and s1_0.is_deleted=false
fetch first 1000 rows only;
개선 효과는 다음과 같습니다:
- 쿼리 1회 실행으로 모든 필요한 데이터를 조회
- 지연 로딩(Lazy Loading)으로 인한 추가 쿼리 제거 (N+1 문제 해결)
- 필요한 필드만 선택적으로 조회 (네트워크 및 메모리 사용 최소화)
DTO Projection 방식은 화면에 필요한 필드만 선택적으로 가져올 수 있기 때문에, API 성능을 높이고 리소스를 절약하는 데 매우 효과적입니다.
N+1 문제를 단순히 없애는 것을 넘어, 보다 명확하고 효율적인 쿼리 구성 방식으로 전환한 것이 핵심입니다.
N+1 해결 성능 재측정 분석
Pinpoint 측정 화면

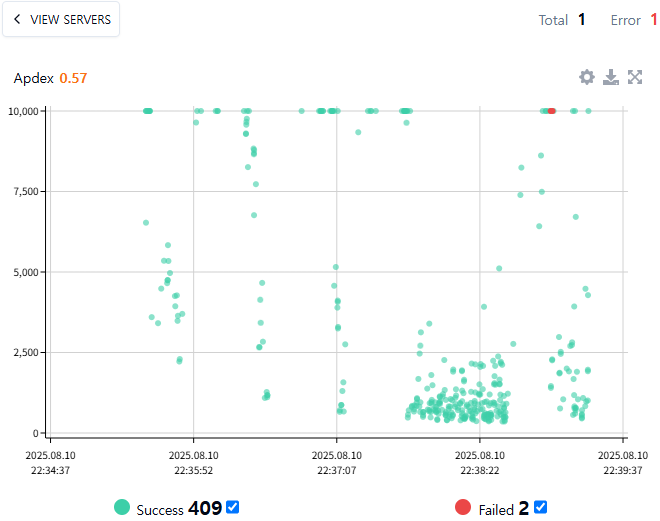



Postman 측정 화면
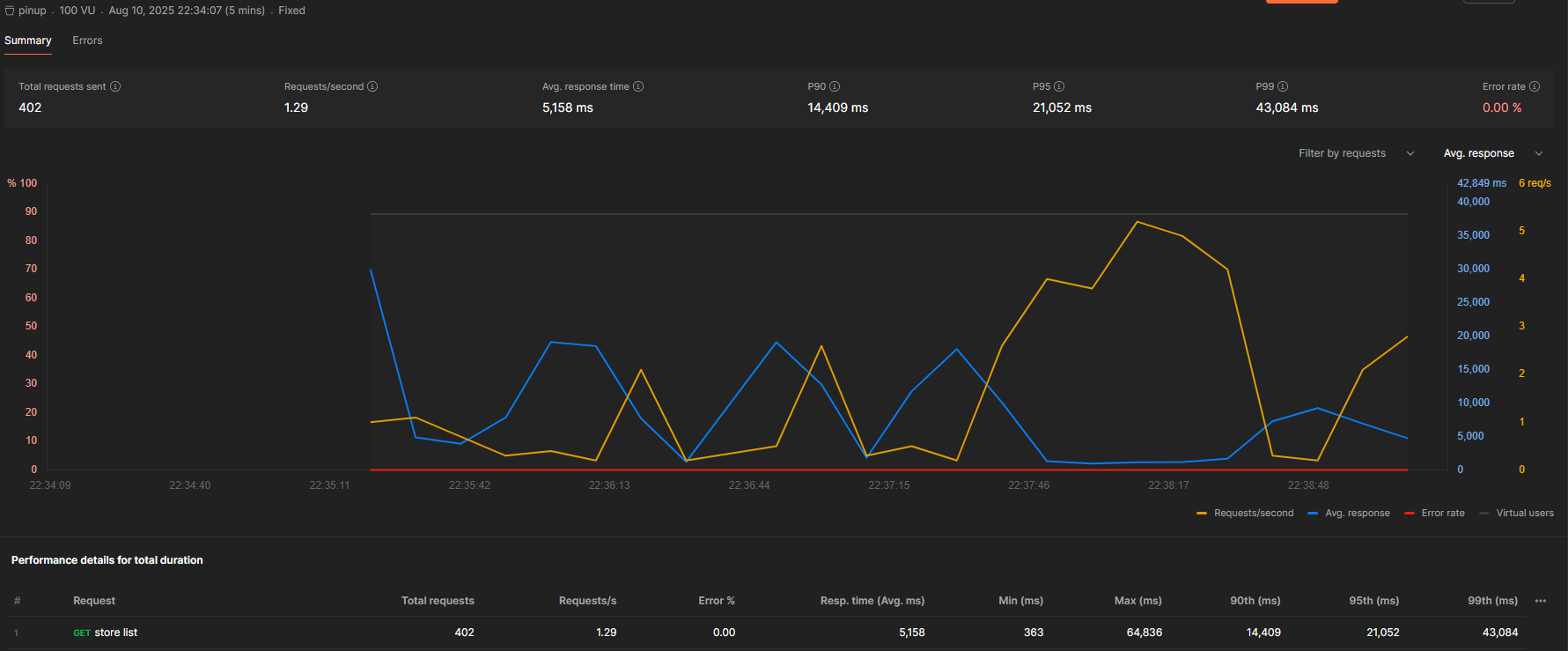
N+1 문제를 개선하면서 에러율은 없어지고 평균 응답 시간도 30초 이상에서 5초 때로 많이 개선 됐지만, executeQuery()인 쿼리 실행 시간이 평균 0.8초 꽤 오래 걸립니다. 그로 인해 getConnection()인 커넥션 연결 요청을 기다리는 시간이 평균 5초 이상으로 너무나 오랜 시간을 차지하고 있습니다. 이 문제를 해결하기 위해 커넥션 풀 크기를 조정하거나 쿼리 튜닝이 필요할 것 같습니다.
커넥션 풀 크기를 조정하는 것은 근본적인 해결책은 아니라 생각이 들었습니다. 사용자가 증가하거나 데이터가 더 많아지면 결국은 똑같은 문제가 발생할 테니까요. 결국은 한계가 있기 때문에 쿼리 성능 개선이 필수적인 것 같습니다.
SQL 쿼리 튜닝(인덱스 Index)
인덱스(Index), 테이블 스캔(Table Scan), 조인 전략(Join Strategy) 등 자세한 내용은 이 컨텐츠에서 다루지 않겠습니다.
쿼리 실행 계획(Query Plan) 확인
쿼리 실행 계획(Query Plan)은 데이터베이스 관리 시스템(DBMS)이 주어진 SQL 쿼리를 처리하기 위해 사용하는 실행 계획입니다. 즉, 쿼리를 어떻게 실행할지에 대한 순서와 방법을 나타내는 정보입니다.
EXPLAIN [ ( option [, ...] ) ] 쿼리문
EXPLAIN [ ANALYZE ] [ VERBOSE ] 쿼리문
options:
ANALYZE [ boolean ]
VERBOSE [ boolean ]
COSTS [ boolean ]
BUFFERS [ boolean ]
TIMING [ boolean ]
FORMAT { TEXT | XML | JSON | YAML }
쿼리 실행 계획으로 확인할 쿼리문은 다음과 같습니다.
explain analyse
select
s1_0.id,
s1_0.name,
s1_0.store_status,
s1_0.start_date,
s1_0.end_date,
c1_0.name,
l1_0.sigungu,
si1_0.image_url
from stores s1_0
join store_categories c1_0 on c1_0.id=s1_0.category_id
join locations l1_0 on l1_0.id=s1_0.location_id
left join store_images si1_0 on s1_0.id=si1_0.store_id
and si1_0.is_thumbnail=true
where s1_0.store_status='RESOLVED'
and s1_0.is_deleted=false
fetch first 1000 rows only;
다음과 같은 실행 계획을 확인할 수 있습니다.
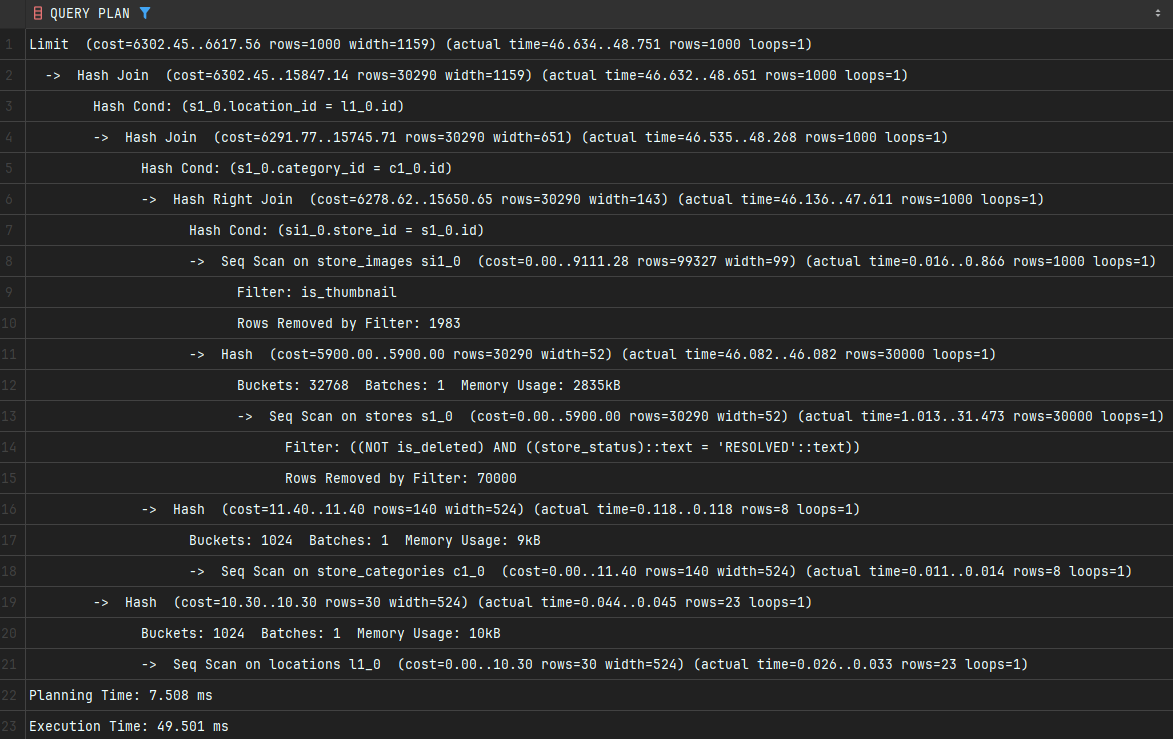
단계별 상세 분석
실행 계획은 노드 단위로 순서에 맞게 읽는 것이 중요합니다. 각 노드는 '->'로 표현이 되고, 루트 노드는 '->'가 붙지 않습니다.
즉, 노드의 총개수는 '->'의 개수 +1입니다. 위의 경우 11개의 노드가 됩니다.
실행 계획을 읽는 순서는 위에서부터 아래로 읽고, 안쪽(들여 쓰기가 가장 깊은 곳)부터 바깥쪽으로 읽으면 됩니다.
테이블 스캔 (Table Scan)
PostgreSQL은 다음의 5가지 스캔 방식을 사용합니다:
- Sequential Scan(Seq Scan)
- Index Scan
- Index Only Scan
- Bitmap Scan(Bitmap Index Scan, Bitmap Heap Scan)
- TID Scan
데이터가 가장 많은 stores, store_images 테이블을 순차 스캔인 "Seq Scan"으로 테이블의 전체 레코드를 순차적으로 읽고 있습니다. 그중 stores는 모든 데이터(10만 건)를 순차적으로 다 읽고 있으며 30.46ms가 소요되었고, 이는 전체 쿼리 실행 시간(49.5ms)의 약 61.5%를 차지하는 성능 병목의 주요 원인 중 하나입니다.
store_categories, locations 테이블도 Seq Scan으로 전체 레코드를 읽고 있지만, 이 두 테이블은 데이터가 매우 작기 때문에 전체 레코드를 읽더라도 순식간에 끝나므로, 성능에 영향을 주고 있진 않습니다.
데이터 결합 (Join Strategy)
PostgreSQL에서 JOIN을 수행할 때 사용하는 실제 알고리즘은 주로 다음과 같이 3가지 방식을 사용합니다:
- Nested Loop Join
- Merge Join
- Hash Join
테이블에서 데이터를 가져온 후, Join 조건에 따라 데이터를 합칩니다. 여기서는 모두 Hash Join 방식으로 사용했습니다.
Hash Join 이란?
두 테이블을 조인할 때, 더 작은 테이블의 조인 키를 이용해 메모리에 '해시 테이블'을 만듭니다. 그리고 큰 테이블을 읽으면서 각 행의 조인 키가 해시 테이블에 있는지 빠르게 찾아보는 방식입니다.
쿼리 실행 계획 시각화
쿼리 실행 결과를 JSON 형식으로 출력하면, 쿼리의 실행 순서, 비용, 버퍼 사용량, Index 사용 여부 등을 상세히 분석할 수 있습니다.
explain (analyse, costs, verbose, buffers, format json)
select
s1_0.id,
s1_0.name,
s1_0.store_status,
s1_0.start_date,
s1_0.end_date,
c1_0.name,
l1_0.sigungu,
si1_0.image_url
from stores s1_0
join store_categories c1_0 on c1_0.id=s1_0.category_id
join locations l1_0 on l1_0.id=s1_0.location_id
left join store_images si1_0 on s1_0.id=si1_0.store_id
and si1_0.is_thumbnail=true
where s1_0.store_status='RESOLVED'
and s1_0.is_deleted=false
fetch first 1000 rows only;
pgAdmin 4를 사용하고 있다면, "Execution Plan" → "Visualize"으로 시각화된 그래프를 확인할 수 있습니다.
이 시각화는 각 노드의 실행 순서와 비용, 행 수, 병렬 처리 여부 등 상세 정보를 시각적으로 제공합니다. 또한 각 노드를 클릭하면 상세 데이터를 확인할 수 있습니다.
만약 pgAdmin 4가 설치되어 있지 않다면, 출력된 JSON 결과를 다음 사이트 중 하나에 붙여 넣어 확인할 수 있습니다.(MySQL은 "MySQL Workbench"에서도 확인할 수 있습니다)
explain.dalibo.com
tatiyants postgres query plan visualiztion
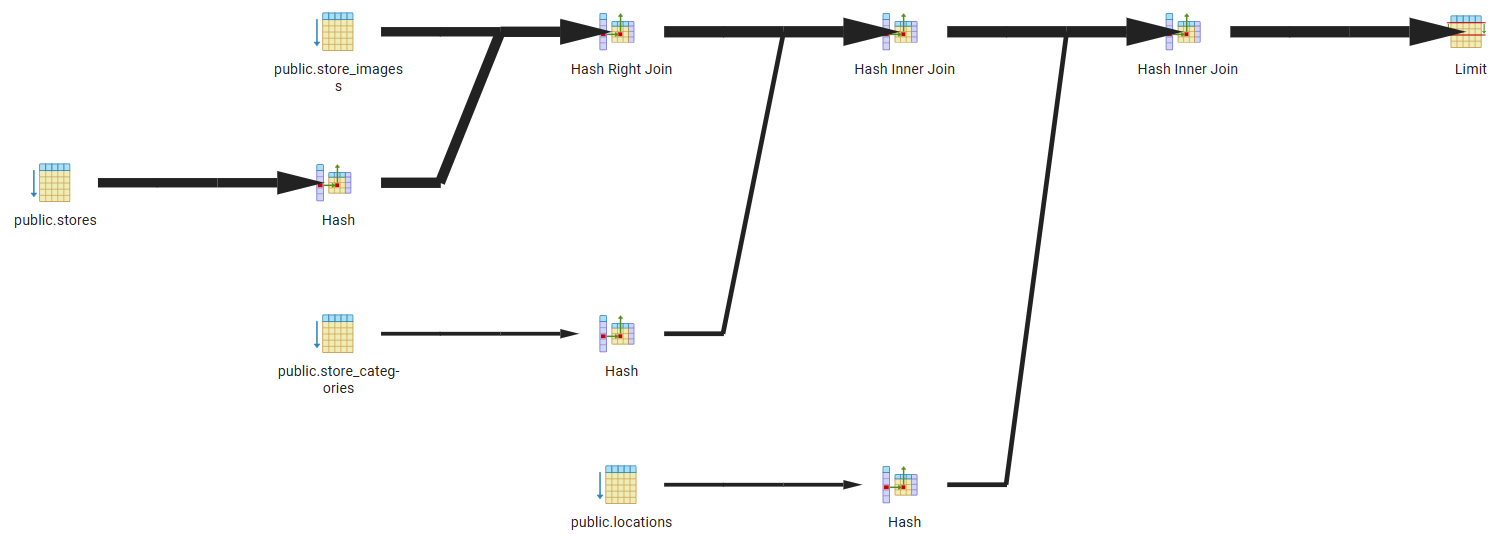
인덱스(Index) 적용
다음과 같이 인덱스를 생성하여 쿼리가 부분 커버링 인덱스(Partial Covering Index)로 타도록 했습니다.
CREATE INDEX idx_stores_status_covering ON stores (store_status, id)
INCLUDE (name, start_date, end_date, category_id, location_id)
WHERE is_deleted = false;
CREATE INDEX idx_store_images_thumbnail ON store_images (store_id)
INCLUDE (image_url)
WHERE is_thumbnail = true;
커버링 인덱스(Covering Index)
쿼리를 충족하는데 필요한 데이터를 인덱스에서 직접 얻을 수 있는 인덱스입니다.
즉, 데이터 테이블 자체에 액세스 할 필요 없이 인덱스에서 쿼리의 모든 필요한 데이터를 찾을 수 있게 합니다.
인덱스 적용 쿼리 실행 계획
다음과 같은 실행 계획을 확인할 수 있습니다.

인덱스 적용 전과 후 비교
| 항목 | N+1만 개선 후 실행 계획 | 인덱스 적용 후 실행 계획 |
| Execution Time | 49.5 ms | 2.7 ms |
| Table Scan | Seq Scan | Index Only Scan |
| Scan Actual Time | 30.46 ms | 0.46 ms |
| Scan Rows | 30,000 rows | 1,000 rows |
쿼리 실행 시간이 49.5ms에서 2.7ms로 단축시켜 약 95%의 성능 개선이 되었습니다.
인덱스 적용 쿼리 실행 계획 시각화

이미지와 같이 테이블 대신 B-Tree가 보이고 적용한 인덱스명을 확인할 수 있습니다.
인덱스 적용 성능 재측정 분석
Pinpoint 측정 화면



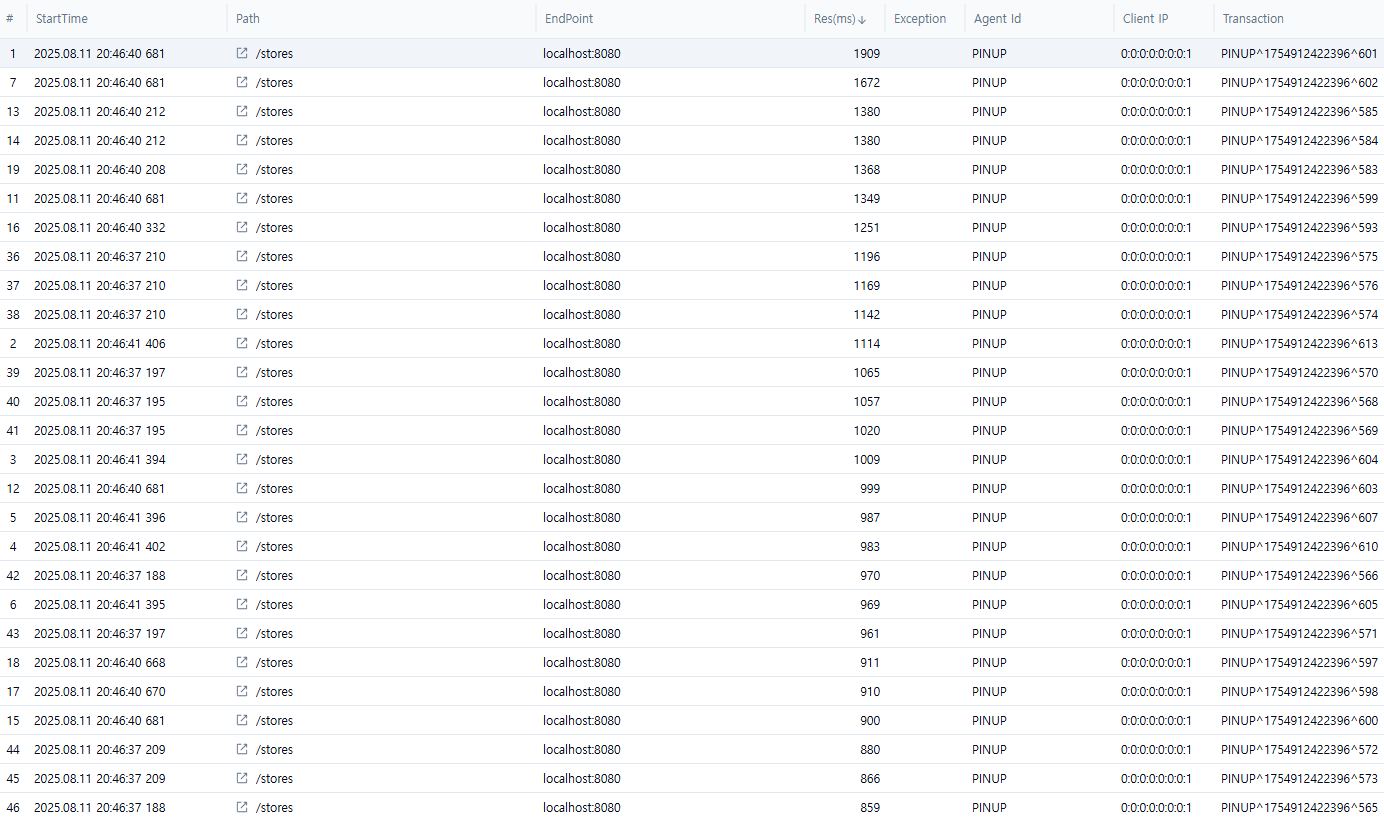

Postman 측정 화면

처음 평균 응답 시간이 33초에서 5초로, 인덱스 적용 후 1초로 개선된 것을 볼 수 있습니다.
다만 1초 미만을 기대했는데 조금 아쉽습니다. 다음 파트에서는 트랜잭션 최적화를 진행해 보겠습니다.
🔗 Reference
'spring' 카테고리의 다른 글
| 애플리케이션 성능 개선 Part 2 (feat. 트랜잭션) (0) | 2025.10.11 |
|---|---|
| Spring Data JPA @Transactional 이해하기 (0) | 2025.09.22 |
| Spring REST Docs API 문서화 (0) | 2025.05.09 |
| [Spring] 인터셉터(Interceptor) 적용 (0) | 2022.04.17 |
| JPA @MappedSuperclass (0) | 2022.03.07 |



